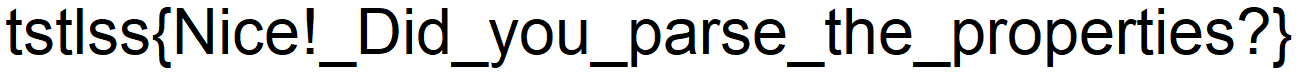CTF Writeup - TastelessCTF 2020 - 7/12
06 Oct 2020
Tags:
ctf
steganography
file formats
Introduction
We want to extract our flag from multiple 7zip files, which happen to only contain junk files.
When dealing with binary formats, Kaitai Struct provides a mapping from bytes to data structures. Unfortunately, there was no parser available for 7zip, so I turned to the proprietary alternative: 010 Editor, which does have a template for 7zip. However, we will see that it doesn’t have full support…
Description
Hint: “If you have trouble solving 7/12, it may makes sense to understand the solution for 7/11!”
Task “7/11” introduces us to the metadata field NextHeaderOffset. At a high level, a 7zip file is structured with the following fields:
- SignatureHeader
- Signature (aka. magic bytes `37 7a bc af 27 1c`)
- ArchiveVersion
- StartHeaderCRC
- StartHeader
- NextHeaderOffset
- NextHeaderSize
- NextHeaderCRC
- (Compressed Data)
- NextHeader
Note that manually increasing the value of NextHeaderOffset allows a payload to be introduced after the compressed data, without disrupting decompression. In the case of task “7/11”, it was a container with a payload consisting of password-protected files for this task, whereas the password was found in the compressed data.
Analysis
Taking into account the payload from the previous task, we might as well look at the final bytes of these files:
xxd part2_0.7z
# 000001e0: ea2e d5e4 02c1 041c 3056 ae14 013d 3b25 ........0V...=;%
# 000001f0: 6eb3 b127 0ec2 997f 0d8e 90ba 2823 1100 n..'........(#..
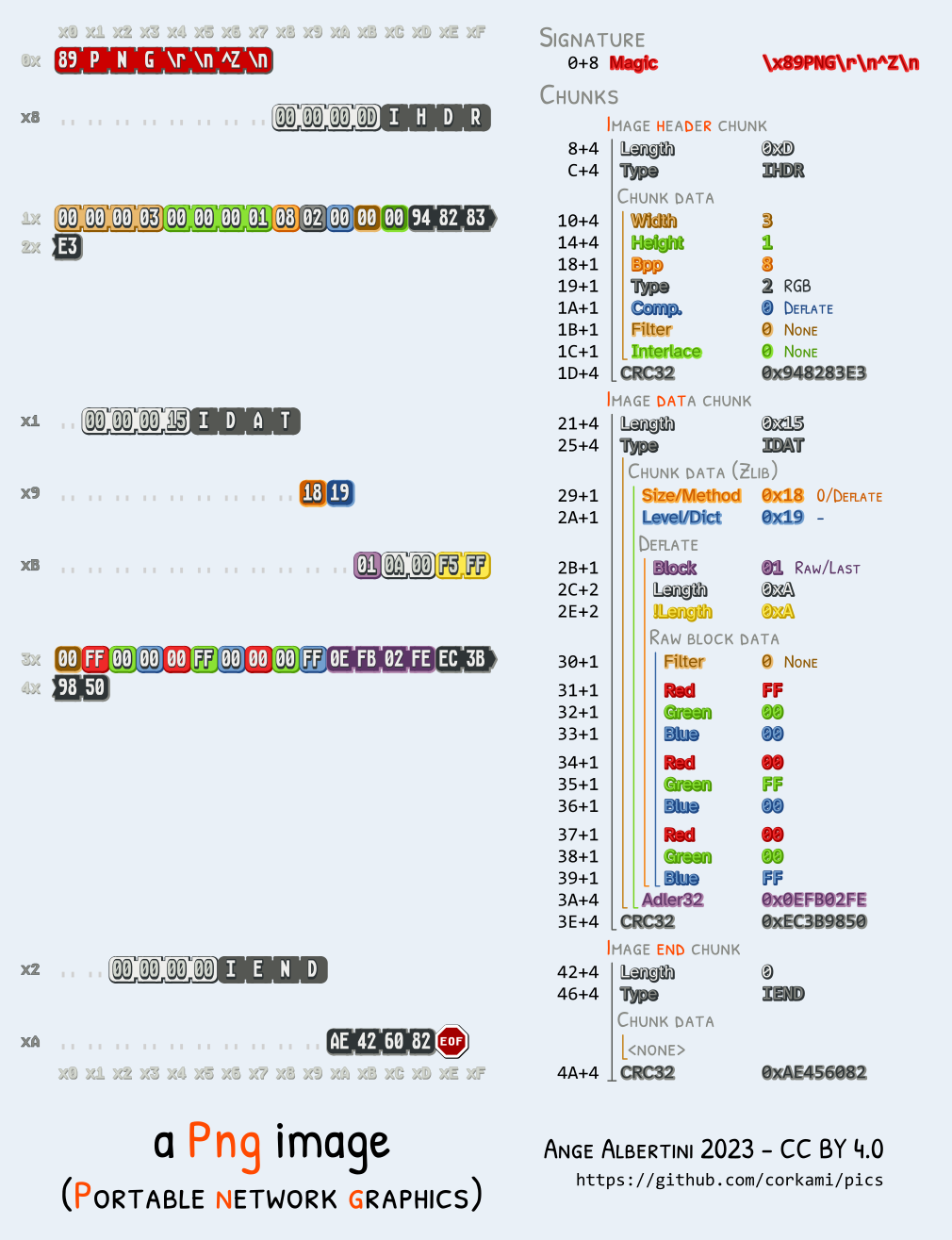
# 00000200: 8950 4e47 0d0a 1a0a 0000 000d 4948 4452 .PNG........IHDR
# 00000210: 0017 0681 6001 0980 8000 070b 0100 0123 ....`..........#
# 00000220: 0301 0105 5d00 1000 000c 80d6 0a01 6913 ....].........i.
# 00000230: 2c7f 0000 ,...
xxd part2_1.7z
# 00000290: 31e1 38fb 8946 ad5c d798 2f81 93ae c6af 1.8..F.\../.....
# 000002a0: a148 0aa0 579e fcb2 7e43 d531 0126 60d2 .H..W...~C.1.&`.
# 000002b0: 7264 3d00 0514 0000 0048 0806 0000 0087 rd=......H......
# 000002c0: 9279 c300 0000 0173 5247 4200 1706 8207 .y.....sRGB.....
# 000002d0: 0109 808c 0007 0b01 0001 2303 0101 055d ..........#....]
# 000002e0: 0010 0000 0c80 fa0a 0167 2436 2900 00 .........g$6)..
xxd part2_2.7z
# 000000b0: 8dad 47aa 1a28 5883 f84d 0146 6ff3 218d ..G..(X..M.Fo.!.
# 000000c0: fc5c 4f82 01b3 d38b 3663 c6fb f058 07d0 .\O.....6c...X..
# 000000d0: 4d80 fe9b 9cde 861e 26a7 68a1 3797 22ba M.......&.h.7.".
# 000000e0: f981 aece 1ce9 0000 0004 6741 4d41 0000 ..........gAMA..
# 000000f0: b18f 0bfc 6105 0000 0009 7048 5973 0000 ....a.....pHYs..
# 00000100: 1706 5d01 0965 0007 0b01 0001 2303 0101 ..]..e......#...
# 00000110: 055d 0010 0000 0c7e 0a01 cfa9 5b61 0000 .].....~....[a..
If we lookup strings IHDR, sRGB, gAMA... we confirm that these are chunks from the PNG file format. Ok, we get the idea: concatenate these payloads to form a valid PNG. At least these chunks seem to be in order. However, it is not clear where the compressed data ends and the PNG data begins.
{kind=link}
My first approach was to extract each container, and recreate them again with the same junk files. After all, we have all we need: the contained files and the compression method (LZMA2:12, which is the default, validated with 7z -slt l):
mkdir ./part2_repacked
cp ./part2/*.7z ./part2_repacked/
cd ./part2_repacked
for i in *.7z; do
7z x "$i"
rm -f "$i"
7z a "$i" *.bin
rm -f *.bin
done
We should be able to calculate the difference in size of compressed data (i.e. Packed Size, also provided by 7z -slt l) between the original archive with the PNG payload and the repacked archive without such payload. In summary, skip the initial headers + the compressed data size of the repacked archive, and extract bytes up to the start of the final header (i.e. NextHeaderOffset).
However, this produced an invalid PNG. I had to download a PNG file with the same chunks and work from there, to understand what was wrong. Recalling the PNG format, we can see that a chunk ends with a CRC32 value, followed by the size and id of the next chunk. After inspecting the extracted bytes from the two first 7zip files, I noticed that my header chunk was larger than expected, since the next id appeared too late.
Apparently, Packed Size does not include all the compressed data. Let’s diff an original archive with a repacked archive in 010 Editor (Tools > Compare Files... > Comparison Type = Binary):
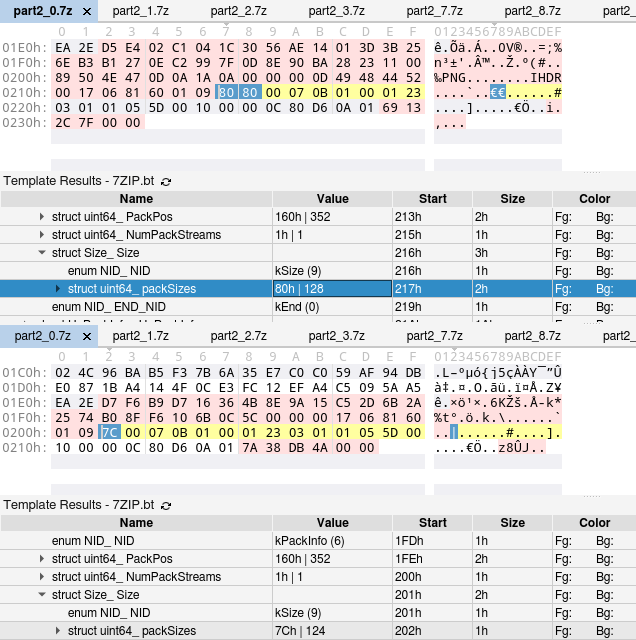
Our NextHeader is identified as EncodedHeader, with the following structure (some fields omitted):
- PackInfo
- PackPos
- Size
- packSizes
- (array of byte values)
By comparing a few other archives, we conclude that the PNG data starts at PackPos + max(i for i in packSizes) (it adds up to the start of the next header in the repacked archive). The value of PackPos matches the Packed Size reported by 7z -slt l. Notice an idiosyncrasy in the packSizes field: if the first byte is >= 0x80, then the value to read is the least significant nibble of the first byte (for the original part2_0.7z it is 0) plus the value of the next byte.
Is that all? Nope! We compared archives with multiple junk files, how about archives with a single junk file?
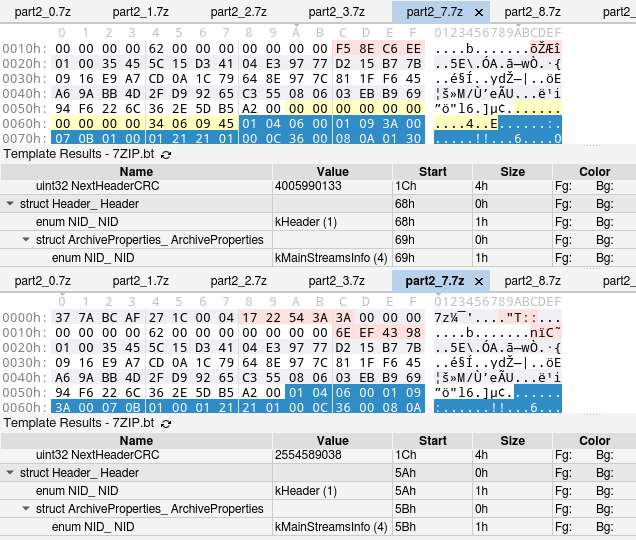
So now our NextHeader is just labelled Header and contains two ids, skipping the rest of the fields… Luckily it’s not an issue, and we can continue to stubbornly avoid reading specifications! Remember that PackPos is reported by 7z, so we can search for that value after the ids, and we get its position in the header. The same >= 0x80 idiosyncrasy applies to this field. What about max(i for i in packSizes)? Apparently, since only a single file was compressed, there are no such values. Therefore, the compressed data actually ends at PackPos, so we just need to take the remaining bytes (highlighted in yellow).
Armed with this rudimentary knowledge, the following script was written to extract the PNG data from a 7zip file:
import os, sys
LOG = 'LOG' in os.environ
def log(message):
if LOG:
print(message)
# Parse original archive
with open(sys.argv[1], "rb") as f:
contents = f.read()
raw_offset = contents[0xC:0xF]
next_header_offset = int.from_bytes(raw_offset, byteorder="little")
log(f"next_header_offset: {next_header_offset}")
# SignatureHeader + StartHeader
start_header_size = 0x20
next_header_pos = start_header_size + next_header_offset
nid = contents[next_header_pos : next_header_pos + 1]
# Generic Header
if nid == b"\x01":
raw_pack_pos = contents[next_header_pos + 6 : next_header_pos + 8]
pack_pos = raw_pack_pos[0]
if raw_pack_pos[0] >= 0x80:
raw_pack_pos = bytes([raw_pack_pos[1], raw_pack_pos[0] & 0x0F])
pack_pos = int.from_bytes(raw_pack_pos, byteorder="little")
log(f"pack_pos: {pack_pos}")
# Not applicable to single file archives
pack_sizes = 0
log(f"pack_sizes: {pack_sizes}")
# Encoded Header
else:
pack_pos_offset = 0
raw_pack_pos = contents[next_header_pos + 2 : next_header_pos + 4]
if raw_pack_pos[0] < 0x80:
pack_pos_offset = -1
pack_pos = raw_pack_pos[0]
else:
raw_pack_pos = bytes([raw_pack_pos[1], raw_pack_pos[0] & 0x0F])
pack_pos = int.from_bytes(raw_pack_pos, byteorder="little")
log(f"pack_pos: {pack_pos}")
# Maximum of all pack sizes
raw_pack_sizes = contents[
next_header_pos + 6 + pack_pos_offset : next_header_pos + 8 + pack_pos_offset
]
pack_sizes = 0
for i in raw_pack_sizes:
if i > pack_sizes:
pack_sizes = i
log(f"pack_sizes: {pack_sizes}")
begin = start_header_size + pack_pos + pack_sizes
log(f"PNG begin: {start_header_size} + {pack_pos} + {pack_sizes} = {hex(begin)}")
end = start_header_size + next_header_offset
log(f"PNG end: {start_header_size} + {next_header_offset} = {hex(end)}")
png_part = contents[begin:end]
sys.stdout.buffer.write(png_part)
After running the extraction script for each archive and concatenating all PNG data:
rm -f flag.png
ls -1 ./part2/ | sort -V | while IFS= read -r i; do
./7z_solution.py ./part2/"$i" >> flag.png
done
We get the flag: