Deceitful Zip
29 Sep 2019
Tags:
compression
cryptography
file formats
lookup magic
visualization
What appeared to be a regular zip file could not be successfully extracted. Each extracted file would be empty or contain junk bytes. The file hierarchy could be read, and none of those files were password protected. Could there be some actual corruption in the zip, or was something else going on?
Analysis
Various extractors complained about corrupted data, or crashed in mysterious ways, such as jar xvf with java.io.IOException: Push back buffer is full.
Our zip was an instance of a xod, which is a web optimized xps used by the web viewer PDFTron. A xps is functionally similar to a pdf: it is organized as a hierarchy of pages (xml) and detached resources contained in those pages (fonts and images). The xod has some changes in the hierarchy, but the underlying implementation uses the same xml elements as a xps.
We can grab a xod example and list files with unzip -l (to improve readability, the following was formatted with tree):
.
├── Annots.xfdf
├── [Content_Types].xml
├── Document
│ ├── DocProps
│ │ └── core.xml
│ └── FixedDocument.fdoc
├── FixedDocumentSequence.fdseq
├── Fonts
│ ├── 0a362aa2-30ce-bf6f-e547-af1200000000.odttf
...
│ └── 0a362aa2-30ce-bf6f-e547-af1200000009.odttf
├── Images
│ ├── 1.jpg
│ └── 3.jpg
├── Pages
│ ├── 1.xaml
│ ├── 2.xaml
│ └── _rels
│ ├── 1.xaml.rels
│ └── 2.xaml.rels
├── _rels
├── Struct
│ ├── 1.xml
│ ├── 2.xml
│ └── font.xml
└── Thumbs
├── 1.jpg
└── 2.jpg
This hierarchy matches the one present in the invalid zip.
Hypothesis: It seems all files are present, so maybe our issue is in the metadata.
Attempting to fix it with zip -F or zip -FF didn’t work (the latter recreates the central directory listing, so that can be ruled out of the issue). Therefore, a manual approach was needed.
To explore this metadata and check if all its values were valid, we used kaitai_struct, in particular the Web IDE:
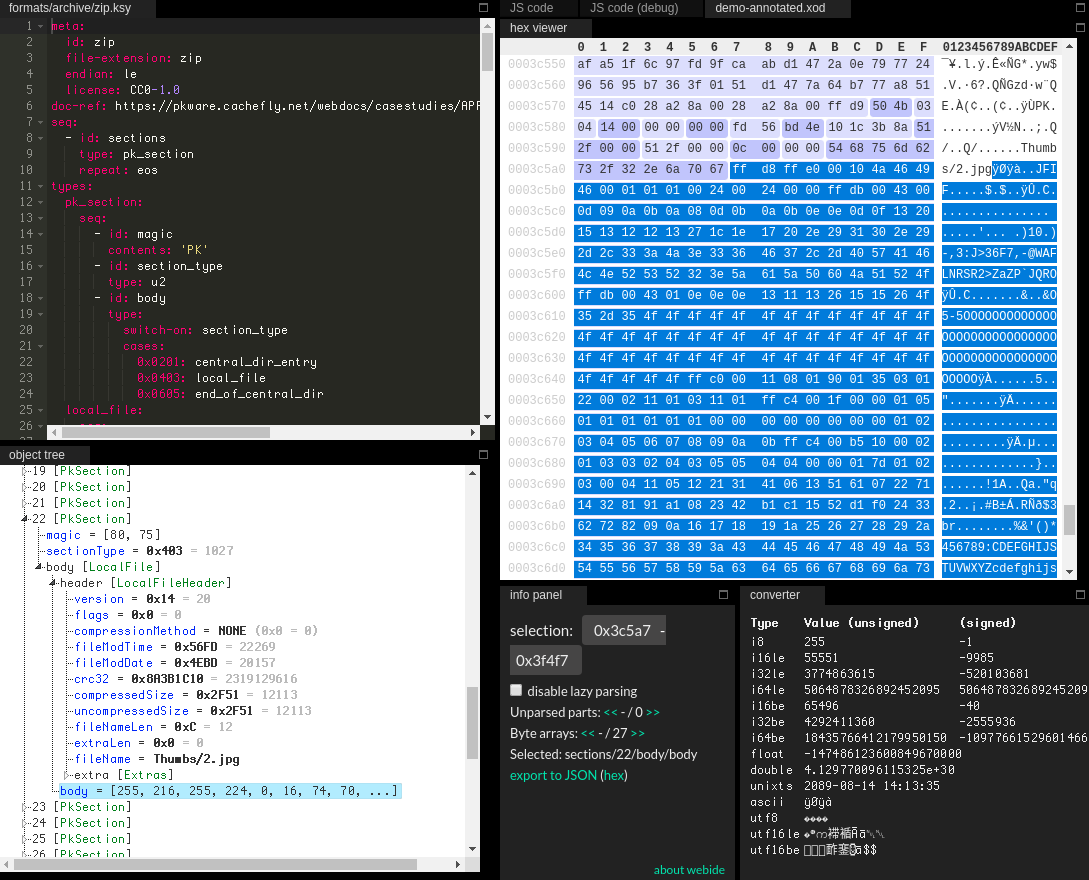
In addition to the IDE, a parser can be generated, so that general purpose scripting can be done on a zip file:
git clone --recursive https://github.com/kaitai-io/kaitai_struct.git
./kaitai-struct-compiler-0.8/bin/kaitai-struct-compiler \
--target python \
./kaitai_struct/formats/archive/zip.ksy
Each compressed file is represented by a PkSection field, with its corresponding metadata contained in PkSection/LocalFile/LocalFileHeader and its compressed data contained in PkSection/LocalFile/body.
To iterate through all PkSection fields in our scripts, the generated parser was modified to keep track of each starting address:
@@ -253,6 +253,7 @@
self._read()
def _read(self):
+ self.global_pos = self._io.pos()
self.magic = self._io.ensure_fixed_contents(b"\x50\x4B")
self.section_type = self._io.read_u2le()
_on = self.section_type
We can aggregate the files under observation by file type.
Text files (e.g. xml) are always compressed (compressionMethod = DEFLATED), while image files (e.g. jpg) are left uncompressed (compressionMethod = NONE). A jpg can be identified by the string JFIF in the byte sequence FF D8 FF E0 ?? ?? 4A 46 49 46. Since image data is encoded with a lossy compression, these files aren’t compressed again in a zip. That would be a waste of CPU resources due to diminishing returns.
As a result, the magic bytes of a jpg file are preserved inside the body field. Even if this file format didn’t have magic bytes, we could still observe other artifacts, such as sequences of bytes with the same value.
When comparing fields of this example zip with the invalid zip, some differences become explicit:
- Image files don’t have magic bytes. Instead, the body seems to have a random distribution of byte values, similar to compressed text files.
- CRC values are zero for all files. This checksum is used to ensure the integrity of decompressed data is preserved after extracting these files from the zip. While this is an optional check done by decompressors, by default a compressor will calculate these values. We can confirm it isn’t needed by taking a valid zip, patching the CRC value to
0, then runningjar xvf, which will successfully extract the file with the following warning:java.util.zip.ZipException: invalid entry CRC (expected 0x0 but got 0xd0d30aae). - The compressed data doesn’t match the specification of the
DEFLATEalgorithm. The header format describes the first 3 bits of a compressed stream as:
First bit: Last-block-in-stream marker:
1: this is the last block in the stream.
0: there are more blocks to process after this one.
Second and third bits: Encoding method used for this block type:
00: a stored/raw/literal section, between 0 and 65,535 bytes in length.
01: a static Huffman compressed block, using a pre-agreed Huffman tree.
10: a compressed block complete with the Huffman table supplied.
11: reserved, don't use.
Therefore, it would be unexpected if bit sequences 110 or 111 were present. We grabbed a valid xod with a larger file count, similar to the one in the invalid zip file, to count and compare the first 3 bits of each PkSection/LocalFile/body inside each zip:
DEFLATE compressed files in a valid vs an invalid zip:




For the valid zip, compressed bits follow the protocol by not matching the reserved method 11; uncompressed bits 111 match the first magic byte of jpg files, while 001 match the first magic byte of png files.
For the invalid zip, we do get unexpected sequences, proving that the compressed data isn’t just a DEFLATE stream.
Reversing the body encoding
Hypothesis: The value reported in PkSection/LocalFile/LocalFileHeader/compressedSize doesn’t match the actual body length.
If this was the case, kaitai_struct would error out while parsing the file. In addition, this can be easily checked by subtracting the addresses of the next PkSection magic bytes with the start of the body.
Hypothesis: Another compression method is actually being used, but it was overwritten with DEFLATE and NONE.
These methods can be ruled out by bruteforcing through all possible values, with the following steps:
- copy bytes of a
PkSectionto a new file (skip the central directory, since it’s optional for decompressing); - set field
PkSection/LocalFile/LocalFileHeader/compressionMethodto a value in range0-19or95-98; - extract the new file.
Hypothesis: There is password protection, but the metadata that specifies this feature was cleared.
Marking a file in a zip as password protected is as simple as setting fields PkSection/LocalFile/LocalFileHeader/flags and PkSection/CentralDirEntry/flags with value 1.
We still need a password. The invalid zip is used by a closed-source application. After decompiling it, finding the hardcoded password was just a matter of running a proximity search for keywords xod and password:
grep -A 10 -B 10 --color=always -rin 'xod' . | \
tee >(grep -i 'password')
However, simply using the password didn’t result in a successful extraction.
Hypothesis: Compressed data is an encrypted stream.
According to the PDFTron docs, AES encryption can be applied to a xod 1. In our application, we can find the call to the mentioned web worker constructor (which is how we found out that PDFTron was being used, in addition to keywords DecryptWorker.js window.forge aes).
The SDK is available for download with npx @pdftron/webviewer-downloader.
The decryption web worker lies within the suggestive file webviewer/public/lib/core/DecryptWorker.js.
We now have all the pieces to decrypt our files: encryption method (AES), password and filenames (both are used to build the AES key), and the source code for decryption. It’s just a matter of getting it to run.
After decrypting the files, those that were compressed with DEFLATE still needed to be “inflated”.
With the files decrypted and decompressed, we can put them under the same filesystem hierarchy as described in the original zip, then create a new zip with that directory’s contents. The result will be a valid unencrypted xod.
Source code
Available in a git repository.
-
Despite the zip file format supporting AES encryption with compression method 99, these
xodfiles do not have such method set. [return]