Almost UTF-16
15 Jun 2019
Tags:
bugfix
build tools
text encoding
file formats
A text file containing some song lyrics ended up having an encoding issue.
Analysis
Mime type detection was failing:
file -ib lyrics.txt
# application/octet-stream; charset=binary
vim tried to open it with latin1 encoding (shown with :set fileencoding):
1 ÿþB^@o^@t^@a^@n^@i^@c^@a^@l^@ ^@D^@i^@m^@e^@n^@s^@i^@o^@n^@s^@ ^@^@
2 ^@^@
3 ^@-^@ ^@U^@m^@,^@ ^@p^@i^@c^@k^@ ^@a^@ ^@c^@o^@l^@o^@r^@.^@^@
4 ^@-^@ ^@B^@l^@u^@e^@.^@^@
5 ^@-^@ ^@B^@-^@L^@-^@U^@-^@E^@.^@ ^@P^@i^@c^@k^@ ^@a^@ ^@n^@u^@m^@b^@e^@r^@.^@^@
6 ^@-^@ ^@E^@i^@g^@h^@t^@.^@^@
7 ^@-^@ ^@1^@,^@ ^@2^@,^@ ^@3^@,^@ ^@4^@,^@ ^@5^@,^@ ^@6^@,^@ ^@7^@,^@ ^@8^@.^@^@
The candidate encodings vim tries to apply can be checked with :set fileencodings, which lists ucs-bom,utf-8,latin1. So it seems vim just applied the last fallback available.
Gedit tried to fallback to the system locale (UTF-8):
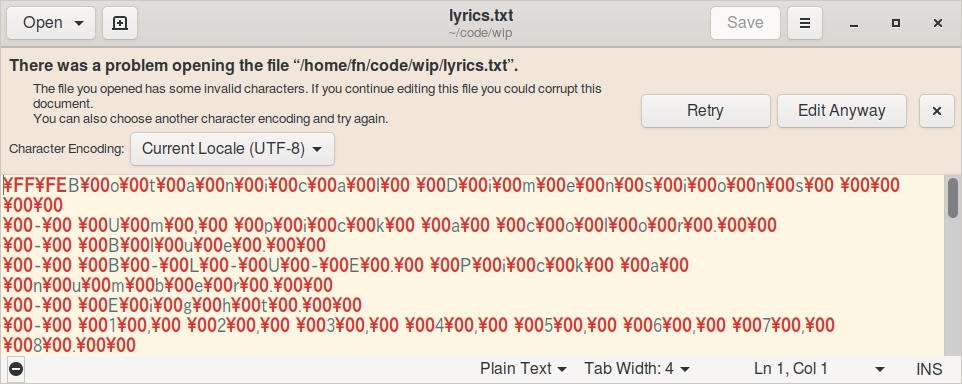
We can make out these patterns:
- Text seems to be mostly ASCII, which is easier seen by stripping non-printable characters:
tr -cd '\11\12\15\40-\176' < lyrics.txt; - Each ASCII character is followed by 1 null byte, which is expected from UTF-16. Example:
for i in ascii utf8 utf16; do printf 'foo' | iconv -t "$i" | xxd; done; - A byte sequence at the beginning:
ff fe. Searching for this pattern confirms this is a Byte order mark (BOM).
Given the order of the bytes in the BOM and the fact it isn’t followed by any null byte (i.e. it is represented by 2 bytes), the expected encoding is UTF-16LE.
Fixing the file
So what went wrong? Let’s try to convert the expected encoding to a simpler encoding, as it would be easier to see where it breaks down due to less encoding artifacts:
iconv -f utf16le -t utf8 < lyrics.txt | xxd
# iconv: incomplete character or shift sequence at end of buffer
# 00000000: efbb bf42 6f74 616e 6963 616c 2044 696d ...Botanical Dim
# 00000010: 656e 7369 6f6e 7320 e0a8 8000 0a2d 2055 ensions .....- U
# 00000020: 6d2c 2070 6963 6b20 6120 636f 6c6f 722e m, pick a color.
# 00000030: e0a8 80e2 b480 e280 80e4 8880 e6b0 80e7 ................
# 00000040: 9480 e694 80e2 b880 000a 2d20 422d 4c2d ..........- B-L-
# 00000050: 552d 452e 2050 6963 6b20 6120 6e75 6d62 U-E. Pick a numb
# 00000060: 6572 2ee0 a880 e2b4 80e2 8080 e494 80e6 er..............
# 00000070: a480 e69c 80e6 a080 e790 80e2 b880 000a ................
# 00000080: 2d20 312c 2032 2c20 332c 2034 2c20 352c - 1, 2, 3, 4, 5,
# 00000090: 2036 2c20 372c 2038 2ee0 a880 e2b4 80e2 6, 7, 8........
# 000000a0: 8080 e490 80e7 8880 e694 80e6 8480 e6b4 ................
# 000000b0: 80e2 8080 e6a4 80e7 8c80 e280 80e6 9080 ................
# 000000c0: e694 80e7 8c80 e790 80e6 a480 e6b8 80e7 ................
# 000000d0: a480 e2b8 8000 0ae0 a880 e2b4 80e2 8080 ................
# 000000e0: e5a4 80e6 bc80 e794 80e2 8080 e6ac 80e6 ................
# 000000f0: b880 e6bc 80e7 9c80 e2b0 80e2 8080 e4a4 ................
# 00000100: 80e2 8080 e6a8 80e7 9480 e78c 80e7 9080 ................
Comparing with an unconverted hex dump:
xxd < lyrics.txt
# 00000000: fffe 4200 6f00 7400 6100 6e00 6900 6300 ..B.o.t.a.n.i.c.
# 00000010: 6100 6c00 2000 4400 6900 6d00 6500 6e00 a.l. .D.i.m.e.n.
# 00000020: 7300 6900 6f00 6e00 7300 2000 000a 0000 s.i.o.n.s. .....
# 00000030: 0a00 2d00 2000 5500 6d00 2c00 2000 7000 ..-. .U.m.,. .p.
# 00000040: 6900 6300 6b00 2000 6100 2000 6300 6f00 i.c.k. .a. .c.o.
# 00000050: 6c00 6f00 7200 2e00 000a 002d 0020 0042 l.o.r......-. .B
# 00000060: 006c 0075 0065 002e 0000 0a00 2d00 2000 .l.u.e......-. .
# 00000070: 4200 2d00 4c00 2d00 5500 2d00 4500 2e00 B.-.L.-.U.-.E...
# 00000080: 2000 5000 6900 6300 6b00 2000 6100 2000 .P.i.c.k. .a. .
# 00000090: 6e00 7500 6d00 6200 6500 7200 2e00 000a n.u.m.b.e.r.....
# 000000a0: 002d 0020 0045 0069 0067 0068 0074 002e .-. .E.i.g.h.t..
# 000000b0: 0000 0a00 2d00 2000 3100 2c00 2000 3200 ....-. .1.,. .2.
# 000000c0: 2c00 2000 3300 2c00 2000 3400 2c00 2000 ,. .3.,. .4.,. .
# 000000d0: 3500 2c00 2000 3600 2c00 2000 3700 2c00 5.,. .6.,. .7.,.
# 000000e0: 2000 3800 2e00 000a 002d 0020 0044 0072 .8......-. .D.r
# 000000f0: 0065 0061 006d 0020 0069 0073 0020 0064 .e.a.m. .i.s. .d
# 00000100: 0065 0073 0074 0069 006e 0079 002e 0000 .e.s.t.i.n.y....
We should have the text “Dream is destiny” near 000000a0 in the converted text, but instead we get a lot of characters in the non-ASCII range. There are also some missing words near 00000030 and 00000060, which in the unconverted text are near 00000060 and 000000a0. A common byte sequence at these positions is 00 0a 00 2d 00. This is suspicious, since the number of bytes is odd. Before this sequence we find 0a 00 or 2e 00, both valid bytes, so the starting null byte hints at a missing char before it. 0a is a line feed (\r). Given that Windows encodes newlines as \r\n, maybe we just need to add a \n before the null byte of the sequence (because in little endian it’s \n\r):
# `sed` can't deal with null bytes properly, so any replacement is done
# in a hex dump and then converted back to hex.
printf "$(od -t x1 -A n -w1 -v lyrics.txt | \
tr -d '\r\n' | \
sed 's/00 00 0a/00 0d 00 0a/gi; s/\s*\([0-f][0-f]\)/\\x\1/g')" \
> lyrics-fixed.txt
Indeed, the file is able to be read correctly:
file -ib lyrics-fixed.txt
# text/plain; charset=utf-16le
A deeper look at mime type detection
I was curious how a single missing byte was making the command file error out, with little feedback given to the user. After looking at it’s manpage, it seemed that option -d would be appropriate, as it prints “internal debugging information”. However, it just dumps attempts at matching all magic number patterns, which seems more useful to test a magic number database file than to figure out incorrect mime type detection. Example output:
14: > 0 string,=\377\376\000\000,"Unicode text, UTF-32, little-endian"]
66 == 0 = 0
bb=[0x7feaf4c0c010,3719], 0 [b=0x7feaf4c0c010,3719], [o=0, c=0]
mget(type=4, flag=0x20, offset=0, o=0, nbytes=3719, il=0, nc=0)
mget/96 @0: \377\376B\000o\000t\000a\000n\000i\000c\000a\000l\000 \000D\000i\000m\000e\000n\000s\000i\000o\000n\000s\000 \000\000\n\000\000\n\000-\000 \000U\000m\000,\000 \000p\000i\000c\000k\000 \000a\000 \000c\000o\000l\000o\000r\000.\000\000\n\000-\000 \000B
118: > 0 search/wt/1,=<?XML,"broken XML document text"]
6 == 0 = 0
bb=[0x55ee5b35db90,1901], 0 [b=0x55ee5b35db90,1901], [o=0, c=0]
mget(type=20, flag=0x40, offset=0, o=0, nbytes=1901, il=0, nc=0)
mget/96 @0: Botanical Dimensions \r\n\r\n- Um, pick a color.\r\n- Blue.\r\n- B-L-U-E. Pick a number.\r\n- Eight.\r\n- 1\000
There are lots of false positives like “broken XML document”, where the text seems pretty readable (even introducing the missing \n!?). Even though there was a pattern for UTF-32, there was none for UTF-16, which seems suprising given that the BOM can be considered as a magic number for UTF-32, so why not UTF-16? Apparently, this particular detection is done in another part of the code, and the debug dump doesn’t include those verifications.
The logic we are interested in is under file encoding.c, in particular these functions:
protected int
file_encoding(struct magic_set *ms, const struct buffer *b, unichar **ubuf,
size_t *ulen, const char **code, const char **code_mime, const char **type)
private int
looks_ucs16(const unsigned char *bf, size_t nbytes, unichar *ubf,
size_t *ulen)
Function file_encoding tests for several character codes and attempts to read the full text as unicode characters. It calls function looks_ucs16, which tests for UTF-161.
Next step was to compile and run file in a debugger.
Going back to the function looks_ucs16, we have the following verifications:
if (bf[0] == 0xff && bf[1] == 0xfe)
bigend = 0; // BOM is little endian
// ...
for (i = 2; i + 1 < nbytes; i += 2) {
// ...
if (ubf[*ulen - 1] == 0xfffe)
return 0; // BOM can't appear again
if (ubf[*ulen - 1] < 128 &&
text_chars[CAST(size_t, ubf[*ulen - 1])] != T)
return 0; // Failed to parse character at ubf[*ulen - 1]
}
// ...
Each parsed unicode character is stored in the buffer ubf, incrementing the length ulen. I set a breakpoint at that last return statement and it was hit. So the BOM was successfully parsed, along with part of the text:
(gdb) p *ulen
$36 = 23
(gdb) p/x *ubf@*ulen
$37 = {0x42, 0x6f, 0x74, 0x61, 0x6e, 0x69, 0x63, 0x61, 0x6c, 0x20, 0x44, 0x69, 0x6d, 0x65, 0x6e, 0x73, 0x69, 0x6f, 0x6e, 0x73, 0x20, 0xa00, 0x0}
(gdb) p/c *ubf@*ulen
$38 = {66 'B', 111 'o', 116 't', 97 'a', 110 'n', 105 'i', 99 'c', 97 'a', 108 'l', 32 ' ', 68 'D', 105 'i', 109 'm', 101 'e',
110 'n', 115 's', 105 'i', 111 'o', 110 'n', 115 's', 32 ' ', 0 '\000', 0 '\000'}
Note that infamous null byte producing an invalid character at ubf[*ulen - 2], which will make the last condition pass with ubf[*ulen - 1].
Further work
Looking at the above parsing done by file, it seems that cases of partial success in text parsing could be communicated to the user, allowing faster identification of corruption. Some possible approaches:
- Provide a percentage of confidence for a given file type, filtered by higher scored types (could be based on total parsed text or statistical analysis of byte histograms). Other heuristics could be explored, such as those from Github’s
linguist. However, there is a risk of being too optimistic, as shown in the following comparison, which uses the python modulechardet:
xxd bom-and-junk
# 00000000: fffe 000a 0000 ......
file -ib bom-and-junk
# text/plain; charset=binary
chardetect bom-and-junk
# bom-and-junk: UTF-16 with confidence 1.0
Another case with the same module:
>>> import chardet
>>> import urllib
>>> detect = lambda url: chardet.detect(urllib.urlopen(url).read())
>>> detect('http://stackoverflow.com')
{'confidence': 0.85663169917190185, 'encoding': 'ISO-8859-2'} # Expected utf-8
>>> detect('https://stackoverflow.com/questions/269060/is-there-a-python-lib')
{'confidence': 0.98999999999999999, 'encoding': 'utf-8'}
- Inform on parsing decisions that were taken and reasons other were not taken (e.g. these 2 bytes should parse to ASCII char, instead they parse to…). Example: Elm’s compiler messages.
-
UCS stands for Universal Coded Character Set, and UCS-16 is an incorrect designation that should be either UCS-2 or UTF-16. [return]